Variant survival screen tutorial¶
GWAS variant screen with per-variant gRNA tiling design, selected based on FACS signal quantiles.
| Library design | Variant (gRNAs tile each target variant) 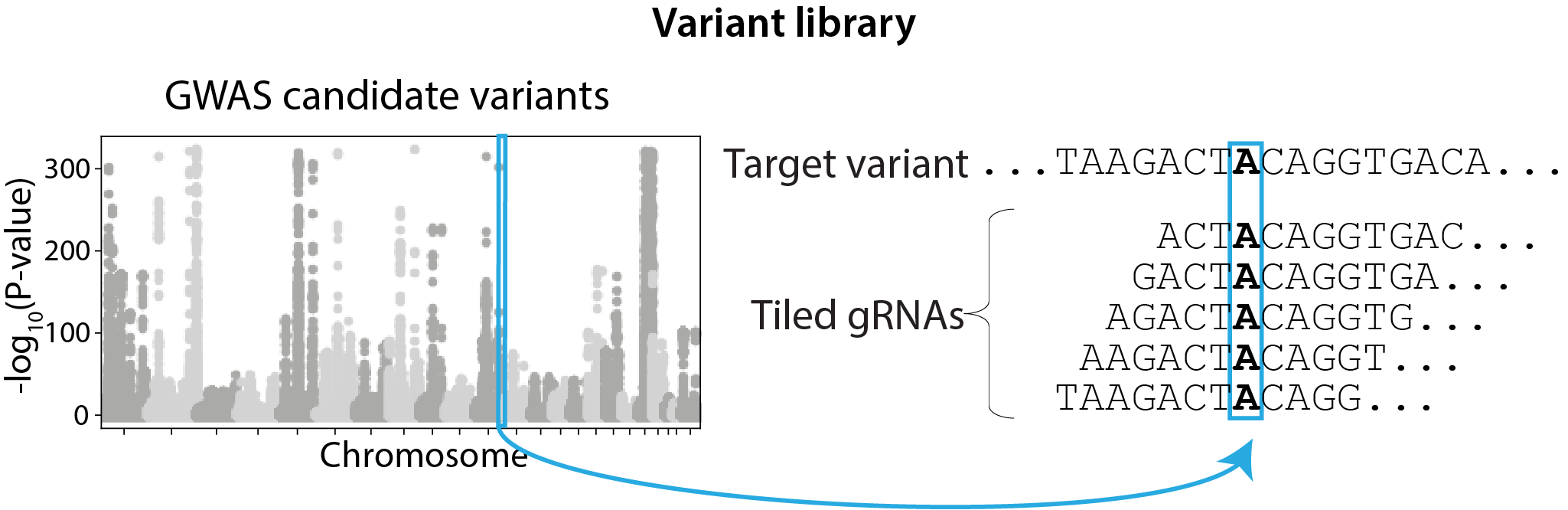 |
|---|---|
| Selection | Cells are grown and will be selected based on their fitness. Cells are sampled in multiple timepoints. 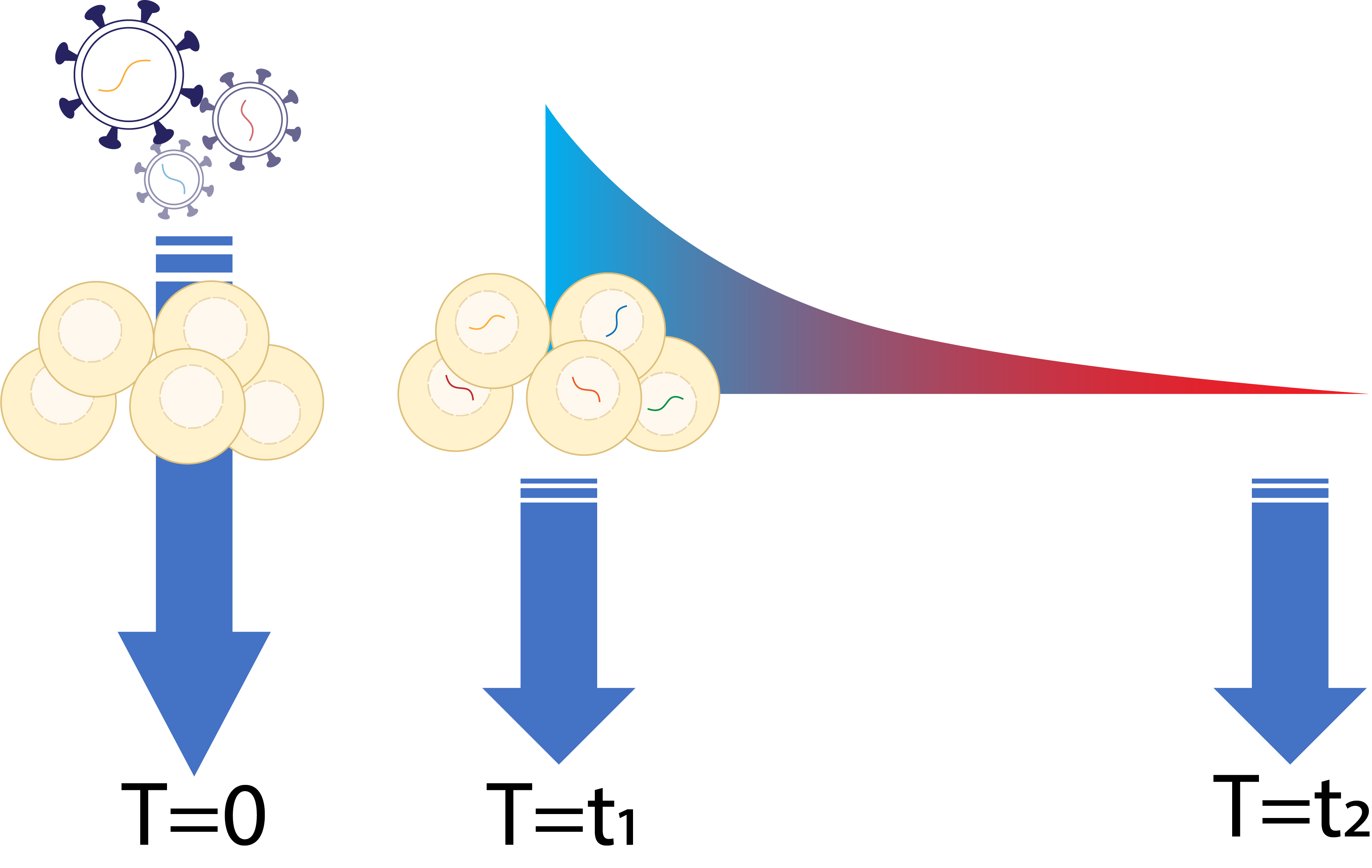 |
For this tutorial, we will consider the following experimental design where the editing rate is measured from the earliest timepoint D7, while we do want to use the initial gRNA abundance from plasmid library.
Example sample_list.csv:
R1_filepath |
R2_filepath |
sample_id |
replicate |
condition |
time |
|---|---|---|---|---|---|
rep1_plasmid_R1.fq |
rep1_plasmid_R2.fq |
rep1_plasmid |
rep1 |
plasmid |
0 |
rep1_D7 _R1.fq |
rep1_D7 _R2.fq |
rep1_D7 |
rep1 |
D7 |
7 |
rep1_D14 _R1.fq |
rep1_D14 _R2.fq |
rep1_D14 |
rep1 |
D14 |
14 |
rep2_plasmid_R1.fq |
rep2_plasmid_R2.fq |
rep2_plasmid |
rep2 |
plasmid |
0 |
rep2_D7 _R1.fq |
rep2_D7 _R2.fq |
rep2_D7 |
rep2 |
D7 |
7 |
rep2_D14 _R1.fq |
rep2_D14 _R2.fq |
rep2_D14 |
rep2 |
D14 |
14 |
Note that time column should be numeric, and condition and time should match one to one.
Example workflow¶
screen_id=survival_var_mini_screen
working_dir=tests/data
# 1. Count gRNA & reporter
bean count-samples \
--input ${working_dir}/sample_list_survival.csv `# Contains fastq file path; see test file for example.`\
-b A `# Base A is edited (into G)` \
-f ${working_dir}/test_guide_info.csv `# Contains gRNA metadata; see test file for example.`\
-o ${working_dir} `# Output directory` \
-r `# Quantify reporter edits` \
-n ${screen_id} `# ID of the screen to be counted`
# count-samples output from above test run is too low in read depth. Downstream processes can be run with test file included in the Github repo.
# (Optional) Profile editing patterns
bean profile tests/data/${screen_id}.h5ad --pam-col '5-nt PAM'
# 2. QC samples & guides
bean qc \
${working_dir}/${screen_id}.h5ad `# Input ReporterScreen .h5ad file path` \
-o ${working_dir}/${screen_id}_masked.h5ad `# Output ReporterScreen .h5ad file path` \
-r ${working_dir}/qc_report_${screen_id} `# Prefix for QC report` \
--lfc-conds D0,D14 `# Conditions to calculate LFC of positive controls` \
-b ` # Remove replicates with no good samples.
# 3. Quantify variant effect
bean run survival variant \
${working_dir}/${screen_id}_masked.h5ad \
-o ${working_dir}/ \
--fit-negctrl \
--scale-by-acc \
--accessibility-col accessibility
See more details below.
1. Count gRNA & reporter (bean count-samples)¶
bean count-samples \
--input ${working_dir}/sample_list_survival.csv `# Contains fastq file path; see test file for example.`\
-b A `# Base A is edited (into G)` \
-f ${working_dir}/test_guide_info.csv `# Contains gRNA metadata; see test file for example.`\
-o ${working_dir} `# Output directory` \
-r `# Quantify reporter edits` \
-n ${screen_id} `# ID of the screen to be counted`
Make sure you follow the input file format for seamless downstream steps. This will produce ./bean_count_${screen_id}.h5ad.
(Optional) Profile editing pattern (bean profile)¶
You can profile the pattern of base editing based on the allele counts.
bean profile tests/data/${screen_id}.h5ad --pam-col '5-nt PAM'
Output¶
Output will be written under ${working_dir}/bean_profile.${screen_id}/. See example output here.
2. QC samples & guides (bean qc)¶
Base editing data will include QC about editing efficiency. As QC uses predefined column names and values, beware to follow the input file guideline, but you can change the parameters with the full argument list of bean qc. (Common factors you may want to tweak is --ctrl-cond=bulk and --lfc-conds=top,bot if you have different sample condition labels.)
bean qc \
${working_dir}/${screen_id}.h5ad `# Input ReporterScreen .h5ad file path` \
-o ${working_dir}/${screen_id}_masked.h5ad `# Output ReporterScreen .h5ad file path` \
-r ${working_dir}/qc_report_${screen_id} `# Prefix for QC report` \
--lfc-conds D0,D14 `# Conditions to calculate LFC of positive controls` \
-b ` # Remove replicates with no good samples.
If the data does not include reporter editing data, you can provide --no-editing flag to omit the editing rate QC.
Output¶
Output will be written under ${working_dir}/. See example output here.
3. Quantify variant effect (bean run)¶
bean run can take 3 run options to quantify editing rate:
From reporter + accessibility
If your gRNA metadata table (${working_dir}/test_guide_info.csvabove) included per-gRNA accessibility score,bean run survival variant \ ${working_dir}/${screen_id}_masked.h5ad \ --control-condition D7 # This allows taking editing pattern from D7 (time=7) to infer unbiased editing pattern in time=0. -o $working_dir \ --fit-negctrl \ --scale-by-acc \ --acc-col accessibility
If your gRNA metadata table (
${working_dir}/test_guide_info.csvabove) included per-gRNA chromosome & position and you have bigWig file with accessibility signal,bean run survival variant \ ${working_dir}/${screen_id}_masked.h5ad \ --control-condition D7 \ -o $working_dir \ --fit-negctrl \ --scale-by-acc \ --acc-bw-path accessibility.bw
From reporter, without accessibility
This assumes the all target sites have the uniform chromatin accessibility.
bean run survival variant \ ${working_dir}/${screen_id}_masked.h5ad \ --control-condition D7 \ -o $working_dir \ --fit-negctrl
No reporter information, assume the same editing efficiency of all gRNAs.
Use this option if your data don’t have editing outcome information.bean run survival variant \ ${working_dir}/${screen_id}_masked.h5ad \ --control-condition D7 \ -o $working_dir \ --fit-negctrl \ --uniform-edit
Output¶
Output will be written under ${working_dir}/. See example output here.
See Subcommands for the full details.
